publications
A list of my research publications organized by categories in reverse chronological order.
2026
-
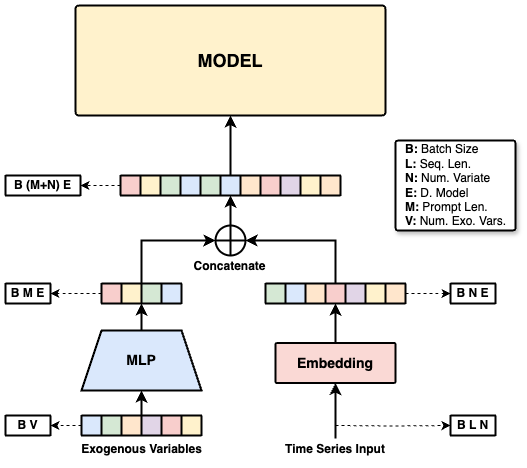 ExoPrompt: Transformer-based greenhouse climate forecasting with structured conditioning and physics-based simulationGürkan Soykan, Önder Babur, Qingzhi Liu, and 1 more authorComputers and Electronics in Agriculture, 2026
ExoPrompt: Transformer-based greenhouse climate forecasting with structured conditioning and physics-based simulationGürkan Soykan, Önder Babur, Qingzhi Liu, and 1 more authorComputers and Electronics in Agriculture, 2026Accurate greenhouse climate forecasting is essential for optimizing crop yield, resource use, and climate control. Traditional physics-based simulators offer interpretability but often rely on simplified assumptions and fixed configurations, while data-driven models struggle with limited generalization due to scarce and localized sensing data. These limitations pose an obstacle to realizing intelligent and adaptive greenhouse systems. Digital twins (DTs), virtual replicas that mirror physical systems, offer a promising paradigm to overcome these constraints and enable real-time decision-making. Addressing this challenge is crucial towards enabling DTs with accurate, adaptive models operating across diverse conditions. We present a simulation-informed framework for robust greenhouse climate forecasting leveraging structured conditioning and synthetic data pretraining. Central to our approach is ExoPrompt, a lightweight conditioning mechanism that encodes environmental, structural, and crop-level attributes into prompt representations, enabling adaptation across diverse scenarios. The model is first pretrained on synthetic data generated using the GreenLight simulator, then fine-tuned on limited sensor data collected under varying lighting conditions. We evaluate our approach on synthetic and real-world datasets across multiple setups. Results show that simulation-based pretraining improves forecasting performance, yielding up to a 46.31% reduction in RRMSE for relative humidity and an 84.94% improvement in CO2 prediction over simulator-only baselines. Conditioning on exogenous parameters further reduces RRMSE by up to 18.79% compared to vanilla models. Finally, we design a controlled simulation experiment varying a single exogenous parameter to isolate and validate the robustness of ExoPrompt under distributional shifts, achieving up to 49.20% RRMSE reduction for CO2 on ground truth data.

2024
- Linguistically-Informed Multilingual Instruction Tuning: Is There an Optimal Set of Languages to Tune?Gürkan Soykan, and Gözde Gül Şahin2024
- ComicBERT: A Transformer Model and Pre-training Strategy for Contextual Understanding in ComicsGürkan Soykan, Deniz Yuret, and Tevfik Metin SezginIn Document Analysis and Recognition – ICDAR 2024 Workshops, 2024
Despite the growing interest in digital comic processing, foundational models tailored for this medium still need to be explored. Existing methods employ multimodal sequential models with cloze-style tasks, but they fall short of achieving human-like understanding. Addressing this gap, we introduce a novel transformer-based architecture, Comicsformer, and a comprehensive framework, ComicBERT, designed to process and understand the complex interplay of visual and textual elements in comics. Our approach utilizes a self-supervised objective, Masked Comic Modeling, inspired by BERT’s [6] masked language modeling objective, to train the foundation model. To fine-tune and validate our models, we adopt existing cloze-style tasks and propose new tasks - such as scene-cloze, which better capture the narrative and contextual intricacies unique to comics. Preliminary experiments indicate that these tasks enhance the model’s predictive accuracy and may provide new tools for comic creators, aiding in character dialogue generation and panel sequencing. Ultimately, ComicBERT aims to serve as a universal comic processor.
- Spatially Augmented Speech Bubble to Character Association via Comic Multi-task LearningGürkan Soykan, Deniz Yuret, and Tevfik Metin SezginIn Document Analysis and Recognition – ICDAR 2024 Workshops, 2024
Accurately associating speech bubbles with corresponding characters is a challenging yet crucial task in comic book processing. This problem is gaining increased attention as it enhances the accessibility and analyzability of this rapidly growing medium. Current methods often struggle with the complex spatial relationships within comic panels, which lead to inconsistent associations. To address these shortcomings, we developed a robust machine learning framework that leverages novel negative sampling methods, optimized pair-pool processes (the process of selecting speech bubble-character pairs during training) based on intra-panel spatial relationships, and an innovative masking strategy specifically designed for the relation branch of our model. Our approach builds upon and significantly enhances the COMIC MTL framework, improving its efficiency and accuracy in handling the unique challenges of comic book analysis. Finally, we conducted extensive experiments that demonstrate our model achieves state-of-the-art performance in linking characters to their speech bubbles. Moreover, through meticulous optimization of each component-from data preprocessing to neural network architecture-our method shows notable improvements in character face and body detection, as well as speech bubble segmentation.
- A Comprehensive Gold Standard and Benchmark for Comics Text Detection and RecognitionGürkan Soykan, Deniz Yuret, and Tevfik Metin SezginIn Document Analysis and Recognition – ICDAR 2024 Workshops, 2024
This study focuses on improving the optical character recognition (OCR) data for panels in COMICS [18], the largest dataset containing text and images from comic books. To do this, we developed a pipeline for OCR processing and labeling of comic books and created the first text detection and recognition datasets for Western comics, called “COMICS Text+: Detection” and “COMICS Text+: Recognition”. We evaluated the performance of fine-tuned state-of-the-art text detection and recognition models on these datasets and found significant improvement in word accuracy and normalized edit distance compared to the text in COMICS. We also created a new dataset called “COMICS Text+”, which contains the extracted text from the textboxes in COMICS. Using the improved text data of COMICS Text+ in the comics processing model from COMICS resulted in state-of-the-art performance on cloze-style tasks without changing the model architecture. The COMICS Text+ can be a valuable resource for researchers working on tasks including text detection, recognition, and high-level processing of comics, such as narrative understanding, character relations, and story generation. All data, models, and instructions can be accessed online (https://github.com/gsoykan/comics_text_plus).
2023
- Identity-Aware Semi-Supervised Learning for Comic Character Re-IdentificationGürkan Soykan, Deniz Yuret, and Tevfik Metin SezginJun 2023
- Comicverse: Expanding the Frontiers of AI in Comic Books with Holistic UnderstandingGürkan SoykanSep 2023Master’s Thesis
Comics are a unique and multimodal medium that conveys stories and ideas through sequential imagery often accompanied by text for dialogue and narration. Comics’ elaborate visual language exhibits variations from different authors, cultures, periods, technologies, and artistic styles. Consequently, the computational analysis of comic books requires addressing fundamental challenges in computer vision and natural language processing. In this thesis, I aim to enhance neural comic book understanding by making use of comics’ unique multimodal nature and processing comics in a character-centric approach. I chose to work on the massive collection of Golden Age of American comics, which is publicly accessible. However, the availability of annotated data is limited. Thus, to achieve my goal, I have adopted a holistic approach composed of four main steps ranging from curating datasets to proposing novel tasks and architectures for comics. The first step involves extracting high-quality text data from speech bubbles and narrative box images using OCR models. I decompose comic pages into their constituent components in the second step through detection, segmentation, and association tasks with a refined Multi-Task Learning (MTL) model. Detection involves identifying panels, speech bubbles, narrative boxes, character faces, and bodies. Segmentation focuses on isolating speech bubbles and panels, while the association task involves linking speech bubbles with character faces and bodies. In the third step, I utilize the paired character faces and bodies obtained from the previous stage to create character instances and, subsequently, reidentify and track these instances across sequential panels. These three steps made locating comic book panels, identifying their components, and transforming character identities into a dialogue-like structure possible. In the final step of my thesis, I propose a multimodal framework by introducing the ComicBERT model, which exploits the abovementioned structure. Cloze-style tasks were used to evaluate ComicBERT’s contextual understanding capabilities. Furthermore, I propose a new task called Scene-Cloze. As a result, my approach achieves a new state-of-the-art performance in Text-Cloze and Visual-Cloze tasks with accuracies of 69.5% and 77.1%, respectively, thus getting closer to the human baseline. Overall, the highlights of my contributions are as follows: 1. I curated and shared COMICS Text+ Dataset with over two million transcriptions of textboxes from the golden age of comics. In addition, I open-sourced the text detection and recognition models that are fine-tuned for the task and datasets used in their training. 2. I refined a MTL framework for detection, segmentation, and association tasks and achieved SOTA results in comic character face and body-to-speech bubble association tasks. 3. I proposed a novel Identity-Aware Semi-Supervised Learning for Comic Character Re-Identification framework to generate unified and identity-aligned comic character embeddings and identity representations. Furthermore, I generated two new datasets: the Comic Character Instances Dataset, encompassing over a million character instances used in the self-supervision phase, and the Comic Sequence Identity Dataset, containing annotations of identities within sets of four consecutive comic panels used in semi-supervision phase. 4. I introduced the multimodal Comicsformer, a transformer-encoder architecture capable of processing sequential panels and their constituents. It serves as the backbone for the Masked Comic Modeling (MCM) task, a novel self-supervised pre-training strategy for comics, resulting in ComicBERT, a potential foundation model for golden age comics. ComicBERT achieves SOTA performance in cloze-style tasks, particularly in text-cloze and visual-cloze tasks, approaching human-level comprehension.